

Understanding conditional probability is key to determining the right maintenance and how it impacts your reliability. This article is to address the difference in the conditional probability of failure patterns, and the impact on how best to maintain assets based upon those differences.
Definition: Conditional probability of failure is defined as the likelihood an item will fail in the next period, assuming it has not yet failed. Editor’s note: for a bit more information on Conditional Probability of Failure and Hazard rates, please refer to this article by our colleague, Mr. Murray Wiseman.
Or put another way, given an item has survived to this point, will its probability of failure increase (e.g. age-related failures), decrease (e.g. infant mortality failures), or remain the same (e.g. random failures).
As part of the Nowlan and Heap study into failures of civilian aircraft published in 1978, they identified six different conditional probability of failure patterns symbolically shown (i.e. not to scale) and the percentage by failure patterns, as follows:
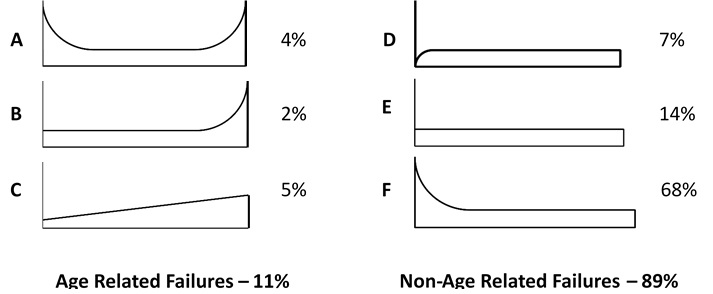 Failure patterns A, B, and C are age/usage related and are caused by degradation caused by age, by exposure to their operating environment, or from their usage. Failure characteristics can include: wear/deterioration; lubrication failures; dirt; falling apart (welds breaking, fasteners loosening); and failures caused by human error that reduce the capability of the asset.
Failure patterns A, B, and C are age/usage related and are caused by degradation caused by age, by exposure to their operating environment, or from their usage. Failure characteristics can include: wear/deterioration; lubrication failures; dirt; falling apart (welds breaking, fasteners loosening); and failures caused by human error that reduce the capability of the asset.
Failure patterns D and E are predominantly random and are caused by events that damage the assets such they can no longer sustain the stress at the time the event occurs, or weaken it to the point that it may fail later with a high level of stress it might otherwise be able to withstand. As they can occur at any time and their probability is the same throughout their lifetime, the failures are considered random. There is no way we can predict when the events may occur and cause failure.
Failure pattern F is predominantly infant mortality, followed by a period of a reduced level of random failures. With infant mortality failures, the item is more likely to fail when first put into service, or be returned to service after work is performed on it (installation, maintenance, turnaround, overhauls). Infant mortality failures can be caused by design errors or bad or marginal design; poor installation; poor assets or substandard parts; and poor workmanship. Many of those causes noted above are project-related (e.g. design, quality of assets, installation) issues, and some are issues related to performing maintenance. For maintenance-related issues, skilled, knowledgeable, and motivated technicians are a big part of the answer for workmanship. For the issue with parts, what about the phone call you get from Purchasing telling you that they “…has sourced the identical part at a big discount…”, but of course, the part is not identical… If the part is of substandard quality and not suitable for use, then it is likely to fail more frequently introducing an infant mortality failure when installed, and any savings in the individual part price can be easily surpassed by: the greater number of parts required; increased labor costs caused by more frequent repairs; and the biggest cost is typically related to the asset being out of service (e.g. reduced output and revenue, expedited shipping, customer service issues, product/service quality issues, etc.).
As assets and systems get more complex, the probability of errors and resulting infant mortality failures can increase.
Impact on Asset Management, Maintenance, and Reliability
To address the different failure patterns, different approaches are required.
Understanding conditional probability – Preventive Maintenance (PM)
For the age/usage-related failures, with sufficient information on failure history, it may be possible to determine when the asset is likely to fail and then take it out of service before it fails. On a routine scheduled basis determined by age or usage, it can then be replaced with a new or rebuilt unit, or the original rebuilt or repaired, and returned to service.
The consequence of failure related to the unscheduled downtime is managed, including:
- reducing secondary damage;
- reducing the long duration of the unscheduled outage and the resulting reduction in output and revenue, especially processes with long ramp up or shutdown periods (i.e. improved Availability);
- impact on customer service (missed deliveries, quality of product or service impact);
- reduce safety or environmental consequence related to unscheduled failures; and
- reduce operating costs related to wasted materials or excessive energy usage.
Understanding condition probability is key here – it increases with age! To be most effective, the work needs to be performed just prior to the age at which it will fail. For the age/usage-related failures just before the rapid increase in the conditional probability of failure in patterns A and B, and when the conditional probability of pattern C reaches a point where it is likely to fail. With failure history, MTBF (Mean Time Between Failure) can be calculated, but preventive maintenance is not performed at the time of MTBF, as by definition, half of the failures would have occurred (assuming symmetrical historical failure curve). The correct timing would be MTBF, minus half of the time of the failure distribution curve, to address variability in failure history.
As there is no increase in the conditional probability of failure in patterns D and E, preventive maintenance is not effective, and a waste of money and resources, and in performing the intrusive preventive maintenance work, might introduce a failure (i.e. pattern F failure). Where pattern F is the dominant failure pattern, then the intrusive preventive maintenance work is not just a waste of money and resources, it potentially resets the infant mortality “clock” and can make it more unreliable.
In preventive maintenance, age or usage is used as a substitute for condition, and to reduce failure consequences, often a conservative approach is taken, especially if there is limited failure history or severe failure consequences, and the asset is taken out of service prematurely before it reaches the end of its lifetime.
If the condition could be effectively measured and in a cost-effective manner, then that needs to be considered in its place, as discussed next.
Understanding conditional probability – Predictive Maintenance / Condition Based Maintenance
For failures with age/usage failures and for most random failures, it may be possible to monitor the condition of the asset. Then based upon condition, either continue to let it operate, if the condition is good, or plan and schedule corrective repairs before it fails. The corrective work might be the same or similar to the work that might be performed if scheduled in preventive maintenance, but it is scheduled based upon condition, not upon age or usage. The benefit of reduced failure consequences is the same as the preventive maintenance listed above.
Understanding condition probability is key here too. It doesn’t change with age, so failures can arise at any time from initial start-up well into the future. We may find ourselves monitoring for a long time! The frequency of the routine scheduled monitoring is dependent upon how much warning (i.e. PF Interval) the condition monitoring method provides. Condition monitoring can be performed through the use of specialized technology or equipment (e.g. vibration analysis systems, infrared thermography, oil analysis, etc.), through monitoring process parameters (e.g. motor current, pressure, flow, temperature, etc.), or through human senses (sight, sound, touch, smell), as it does not need to be expensive or complex if the method provides sufficient lead time to avoid the consequences.
However, for the infant mortality period, there is no condition that can be monitored to warn of the failure with sufficient lead time prior to failure, as it fails immediately or shortly after being put into service, or put back into service. To address infant mortality, one-time changes may provide the required solution, our next discussion topic.
One Time Changes / Re-Design
One time changes can take the form of re-design of the asset itself to make it more reliable (e.g. more robust design, better materials, improve quality of build/installation), or reduce the consequence of failure (e.g. reduce safety or environmental consequences, reduce downtime by improving diagnostics or easier to repair, redundancy).
Also, the processes, procedures, and tasks to operate and maintain the asset can be revised to improve reliability or reduce the failure consequences, as well. To reduce the potential for human error related to not performing the changed activities correctly, they should be documented and be issued as SOP (Standard Operating Procedures) for operators, or job plans for maintainers. This is especially important for events that can cause random failures, and the documentation is critical for procedures that are not frequently performed (e.g. start-up procedures or emergency shutdown of continuous processes).
And the capability of those who operate and maintain the assets can be improved through training, and thus improving reliability and reducing failure consequences.
There still remains a situation where the loss of a protective function caused by the failure is not evident under normal circumstances, our next discussion topic.
Failure Finding Tasks / Functional Tests
As protective devices/systems may operate only under abnormal conditions, it may not be evident, if they are in a failed state under normal circumstances (i.e. hidden failure). With failures having age/usage or random failure patterns where it is not technically feasible AND worth doing a predictive maintenance or preventive maintenance task to effectively address a hidden failure, then it may be possible to perform a failure finding task that will provide a tolerable/effective manner of managing the circumstances.
Run-To Failure
For those situations where the consequences are financial only, and a suitable predictive or preventive (or failure finding task for hidden failure) cannot be found, then it might be appropriate to decide to let it run to failure.
Failure patterns are useful in determining what might not be appropriate tasks given the nature of the failure.
Learn more in our Basic Reliability Management and Reliability Centered Maintenance courses.
This article is authored by Leonard G Middleton for publication and distribution as part of the Asset Management Solutions newsletters. The newsletters are distributed to a number of practitioners, including international practitioners who often have limited information available to them locally.
This is intended to be an overview of the subject written in common language with the minimal required finance and accounting jargon for asset management, maintenance, and reliability practitioners to understand how their efforts contribute to the performance of the organization. It is intended to help them communicate that message within the organization and for the maximum benefit for the organization and its stakeholders.
The author and copyright owner grant Conscious Asset permission to include this article in their Body of Knowledge.
Leonard G. Middleton is an experienced professional with many years of broad professional experience, in Canada, the US, and internationally, He has worked in a number of different roles related to maintenance, reliability, and asset management, program and project management, contracts management, outsourcing, and engineering, in industry and in his consulting roles.
His experience in asset-intensive industries has reinforced his perspective on the importance of the physical assets on the operational cost structure and with that the need to get the assets appropriate to the organizational objectives through projects, and then operating and maintaining them effectively.
Leonard has an undergraduate engineering degree (B.A.Sc.), a graduate business degree (MBA), and holds professional designations in engineering (P.Eng.), project management (PMP), and in Maintenance, Reliability, and Asset Management (CMRP, MMP, CAMA), and is an RCM Practitioner.
Leonard is a long-time member of PEMAC, having served on the national Board of Directors for multiple terms. He is an instructor in both the MMP and AMP programs and is a subject matter expert responsible for the content of two MMP modules
#reliability, #reliabilityengineering, #maintenance, #rcm, #uptime
